
Imagine you’re at a crowded party. Everyone is talking, but you only want to understand one specific conversation. In the past, following a conversation meant listening to each person speak in turn, hoping to catch the relevant bits. This is similar to how traditional machine translation models worked – they processed sentences one word at a time.
But what if you could focus on the people directly involved in the conversation, ignoring the background noise? This is the core idea behind the groundbreaking paper “Attention is All You Need” by Vaswani et al. (2017). Their work introduced the Transformer, a new neural network architecture that revolutionized natural language processing (NLP).
What was The Paper About?
In 2017, a groundbreaking paper titled “Attention Is All You Need” was published by a team of researchers at Google. This paper introduced the Transformer model, a novel deep learning architecture that has since revolutionized the field of natural language processing (NLP) and beyond. The authors of this paper—Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Łukasz Kaiser, and Illia Polosukhin—proposed a model that relies entirely on attention mechanisms, eliminating the need for recurrent neural networks (RNNs) and convolutional neural networks (CNNs).
Understanding Machine Translation: The Importance of Context
Machine translation, the task of converting text from one language to another, has been around for decades. Early models relied on simple rules and dictionaries, often leading to clunky and nonsensical translations.
The rise of neural networks brought significant improvement. These models learn from vast amounts of text data, capturing the complex relationships between words. However, a major challenge remained: context.
Consider the sentence: “The time flies when you’re having fun.” Here, the meaning of “flies” depends heavily on the surrounding words. A traditional, sequential model might translate this literally, missing the intended meaning.
Enter the Transformer: Attention Mechanism Takes Center Stage
The Transformer, proposed by Vaswani et al., addressed this limitation by introducing the attention mechanism. Let’s break it down:
- Attention: Imagine focusing on a specific part of an image while blurring the rest. The attention mechanism works similarly, allowing the model to focus on relevant parts of the input sentence when processing each word.
- Self-Attention: In machine translation, the model attends to the source language sentence to understand the context for each word in the target language. This is called self-attention because the model attends to different parts of the same sentence.
Here’s an analogy: Imagine you’re reading a complex document. You might go back and reread certain sections to understand the flow of ideas. The Transformer’s self-attention allows it to do the same with sentences, dynamically focusing on relevant parts.
Benefits of Attention
- Improved Context: By attending to relevant parts of the sentence, the Transformer captures context more effectively, leading to more accurate translations.
- Long-Range Dependencies: Traditional models struggle with long sentences where dependencies between words are far apart. Attention allows the Transformer to consider these dependencies more easily.
- Parallelization: The attention mechanism can be calculated in parallel, making the Transformer faster to train than sequential models.
The Transformer Architecture: A Deep Dive
The Transformer is a complex architecture, but let’s delve into its core components with a focus on the parts you mentioned:
- Encoder: This part processes the source language sentence. Here’s where the magic happens:
- Self-Attention Layer: Each word in the sentence is compared to all other words using a scoring function. This score reflects the relevance of one word to another. The model then uses these scores to attend to the most relevant parts of the sentence for each word. For example, in the sentence “The cat sat on the mat,” the word “cat” might be more relevant to “sat” than “the.”
- Multi-Head Attention: Imagine having multiple experts attending the party, each focusing on a slightly different aspect of the conversation. Multi-head attention allows the Transformer to attend to the source sentence in multiple “heads,” simultaneously capturing different aspects of the relationships between words. This enriches the understanding of context.
- Feed Forward Network: After the attention layers, a feed forward network is used to further process the information and extract additional features from the sentence.
- Decoder: This part generates the target language sentence word by word. It attends to the encoded source language representation and previously generated words to decide what word to generate next.
- Positional Encoding: Since the Transformer doesn’t process words sequentially, it needs a way to understand the order of words. Positional encoding injects information about a word’s position in the sentence. For example, the word “cat” in the first position will have a different encoding than “cat” in the third position.
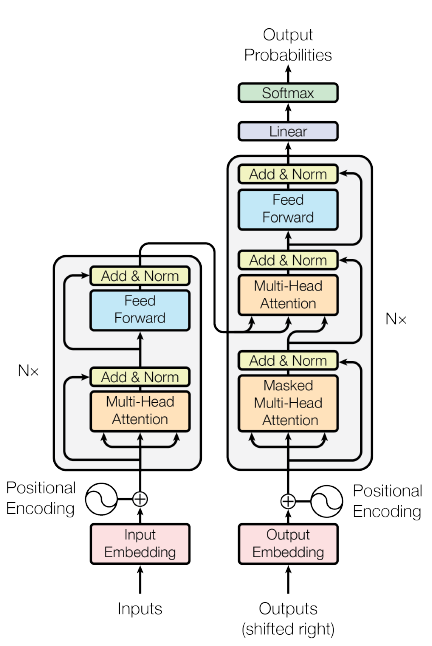
Think of the Transformer as a factory: The encoder takes the raw materials (source language sentence) and processes them through self-attention, multi-head attention, and feed forward networks. The decoder then uses these processed materials and its own knowledge (previously generated words) to assemble the final product (translated sentence).
The Impact of “Attention is All You Need”
The impact of the paper has been profound. Here are some key points:
- State-of-the-Art Machine Translation: The Transformer achieved state-of-the-art performance on machine translation tasks, surpassing previous models. This led to significant improvements in translation quality for various languages.
- Rise of Generative Pre-trained Transformers (GPTs): The Transformer architecture became the foundation for powerful language models like GPT-3, which can generate human-quality text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
- Advancements in NLP: The attention mechanism has been adopted for various NLP tasks beyond translation, including text summarization, question answering, and sentiment analysis.
The attention mechanism is like a light bulb moment in NLP. It provided a powerful way for models to understand context and relationships between words, leading to significant advancements in the field.
The Future of Attention: Beyond Language Processing
The potential of attention goes beyond language. Researchers are exploring its application in other areas:
- Computer Vision: Attention mechanisms can help focus on specific parts of an image for tasks like object detection and image captioning.
- Speech Recognition: Attention can be used to focus on the speaker’s voice and ignore background noise, improving speech recognition accuracy.
Challenges and Considerations: Attention is Not a Magic Bullet
While the Transformer and attention mechanism have revolutionized NLP, there are still challenges to consider:
- Explainability: Unlike traditional rule-based models, understanding how Transformers arrive at their decisions can be difficult. This can be a hurdle for tasks where interpretability is crucial.
- Computational Cost: Training large Transformer models requires significant computational resources and data. This can limit accessibility for smaller research groups or applications.
- Bias: Like any AI model, Transformers can inherit biases from the data they are trained on. Mitigating bias in NLP models is an ongoing area of research.
Looking Ahead: Attention’s Continued Evolution
The field of NLP is constantly evolving, and the attention mechanism is likely to play a central role in future advancements. Here are some exciting possibilities:
- Multimodal Attention: Integrating attention mechanisms with other modalities like vision or speech could enable models to understand the world in a more comprehensive way. Imagine a system that translates spoken language while considering visual context from a video call.
- Lifelong Learning: Current Transformers require vast amounts of data for training. Research on continual learning could allow models to adapt and learn from new data more efficiently.
- Human-in-the-Loop NLP: Attention mechanisms could be used to create more interactive and collaborative NLP systems where humans and machines work together to achieve tasks.
The potential for attention-based NLP models is vast. As researchers continue to explore its capabilities, we can expect even more groundbreaking applications that bridge the gap between human and machine communication.
Conclusion: Attention is Here to Stay
“Attention is All You Need” by Vaswani et al. is a landmark paper that fundamentally changed the landscape of NLP. The attention mechanism has provided models with a powerful tool to understand context, leading to significant improvements in machine translation, text summarization, and other tasks. With ongoing research, we can expect attention to play a pivotal role in shaping the future of human-computer interaction and artificial intelligence.
